

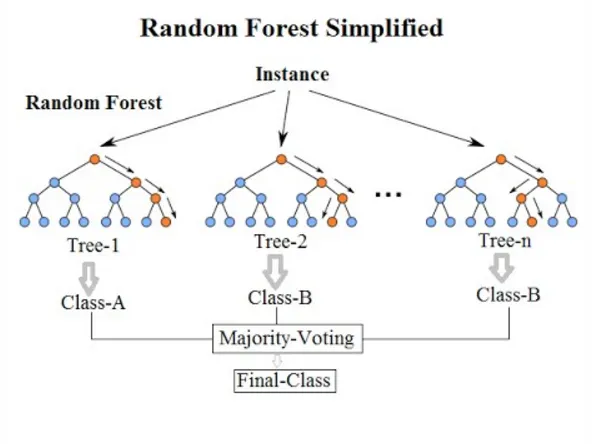
Introduction:
Imagine a vast forest, not of towering trees but of decision trees, each one charting a path to a solution. This is the essence of the Random Forest algorithm, a powerful tool in the machine learning arsenal. In the vast landscape of machine learning algorithms, Random Forest stands out as a versatile and powerful tool for both classification and regression tasks. It is an ensemble learning method that combines the strength of multiple decision trees to deliver robust and accurate predictions. In this blog post, we'll delve into the intricacies of Random Forest, exploring how it works, its applications, and its unique ability to unravel the importance of features in a dataset.
But what exactly is a Random Forest?
Unlike a single decision tree, which can be prone to overfitting and inflexibility, a Random Forest is an ensemble – a team of these trees working together. Each tree is trained on a randomly sampled subset of the data and uses a random subset of features. This diversity prevents any one tree from memorizing the training data and ensures the forest, as a whole, is robust and adaptable.
Random Forest operates by creating a multitude of decision trees during the training phase. Each tree is trained on a random subset of the dataset, and the final prediction is determined by averaging or voting across all trees. This ensemble approach helps in improving the overall accuracy and generalization of the model.
Feature Importance:
One of the standout features of Random Forest is its ability to determine the importance of features within a dataset. This insight is invaluable in understanding the factors that contribute most to the model's predictions. The algorithm assigns an importance score to each feature based on how much it contributes to the reduction in impurity (for example, Gini impurity in classification tasks or mean squared error in regression tasks) across all the decision trees.
This information is crucial for feature selection, guiding data scientists in focusing on the most influential variables. For instance, in a predictive maintenance scenario, where the goal is to anticipate equipment failures, Random Forest could identify which sensor readings or operational parameters are most indicative of potential issues.
So how does this translate to real-world applications?
Let's delve into two common tasks where Random Forests shine:
1. Classification:
Imagine a bank wanting to predict whether a loan application is likely to be successful. A Random Forest can analyze factors like income, credit score, and spending habits, each tree offering a different perspective. The final prediction is the most common vote from the forest, resulting in a more accurate and nuanced assessment than any single tree could provide.
2. Regression:
Now picture a scientist studying the factors influencing crop yields. A Random Forest can analyze weather data, soil composition, and planting techniques, with each tree predicting the yield based on its unique understanding of the data. The average prediction from the forest then offers a reliable estimate, allowing the scientist to optimize farming practices.
Real-life examples abound. Random Forests have been used in:
- Face recognition software: distinguishing faces in crowded photos
- Fraud detection: identifying suspicious financial transactions
- Medical diagnosis: predicting the risk of developing certain diseases
- Financial forecasting: predicting market trends
Conclusion:
References:
- Breiman, L. (2001). Random forests. Machine learning, 45(1), 5-32.
- Liaw, A., & Wiener, M. (2002). Classification and regression by randomForest. R news, 2(3), 18-22.
- Scikit-learn documentation: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- Machine Learning Mastery: https://medium.com/pursuitnotes/random-forest-regression-in-5-steps-with-python-2463b7ae9af8
- A Beginner's Guide to Random Forests: https://towardsdatascience.com/random-forest-explained-6b4849d56a2f
